

Exploring the Data Science Roadmap: A Complete Guide to Your Journey
This will give an overview how and where to start data science, what are the important steps to follow. It also mention key methods as a data s ience should follow. In short, it describe Data science roadmap.
DATA SCIENCE
12/20/20244 min read
In today’s data-driven world, it is a lucrative and rewarding to become a data scientist. Data science is an interdisciplinary field that combines programming, domain knowledge, storytelling, and mathematics, in particular, statistical analysis, linear algebra, and calculus, to extract insights and drive decisions from data. However, breaking into data science can seem daunting due to the vast range of skills required. This roadmap is designed to guide one data scientist enthusiast through the essential steps and skills needed to become a proficient data scientist.
Understanding Data Science
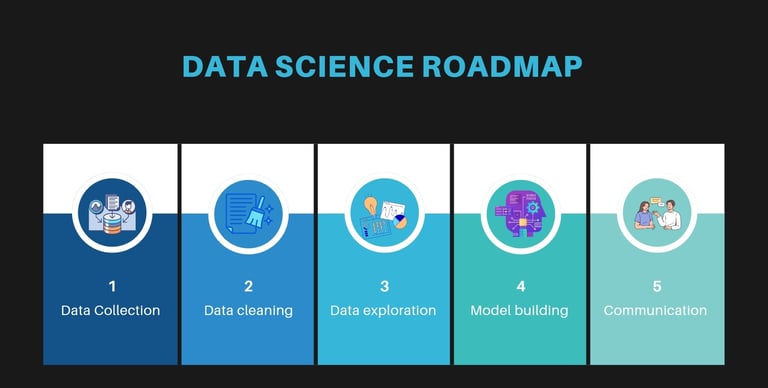
Before diving into the specifics, it's crucial to understand what data science encompasses. Data science involves:
Data Collection: As the area specifies, the first job as a data scientist is gathering data from various sources. Without data, a data scientist is like an artist without a canvas.
Data Cleaning: The next big step as a data scientist is preprocessing and cleaning data for analysis. If somehow a data scientist has data, most of the time, data are unstructured and messy. These unstructured data have no use for data scientists. Data need to be cleaned and structured. Data scientists need clean data like chefs need fresh ingredients.
Data Exploration: This is one of the important steps for data scientists. It helps them get an idea of the data's structure, types, and distribution. By diving into the data early on, they can spot patterns, relationships, and trends right off the bat. Any outliers or anomalies can be guessed from data visualization. Plus, data exploration ensures the data's quality by identifying inconsistencies, missing values, or errors that need cleaning.
Model Building: Based on data exploration, data scientists can start building a predictive model using statistical and machine learning techniques. Model building is where data scientists turn insights into powerful predictive tools.
Communication: All previous steps will go in vain if the data scientist can't convey the findings and predictions to stakeholders in a comprehensible manner. So, communicating is as important as data collection, data cleaning, data exploration, and model building. For data scientists, clear communication turns complex insights into actionable knowledge.
Foundational Skills
Mathematics and Statistics
Mathematics forms the backbone of data science. Therefore, mathematics is a must-have topic for a data scientist, as it helps them to formulate hypotheses, validate results, and derive meaningful insights. In particular, data scientist must have knowledge on
Linear Algebra: Concepts like vectors, matrices, and transformations.
Calculus: Understanding derivatives and integrals, especially in optimization problems.
Probability and Statistics: Fundamental concepts such as distributions, hypothesis testing, regression, and Bayesian statistics.
Programming
Another must-have topic for a data scientist is programming. Proficiency in programming will help them implement data science algorithms. It is not restricted to, the trending programming languages are
Data Manipulation and Analysis
Data Wrangling
One of the crucial steps for a data scientist is cleaning, organizing, and transforming raw data into an appropriate form; that is called data wrangling. It usually involves the following methods:
Missing Values: Missing values carry no meaning, and any mathematical or statistical operation on missing values drives misleading information. Before applying and model or concluding anything from data visualization, one should ensure that there should not be any missing values in the data. There are numerous methods to handle missing values of data, and every method has some advantages and disadvantages. A data scientist has to decide the method wisely.
Data Transformation: Imagine you are analyzing a dataset that contains the height and weight of a group of people; height is measured in cm, and weight is measured in kg. This different scale may skew the analysis. To tackle this kind of scenario, it is necessary to normalize the data. Similarly, data scaling and encoding of categorical variables are also crucial to conclude.
Data Visualization
Sometimes finding insights from data is not easy. In that case, data visualization helps a lot. One can find trends and outliers directly by visualizing the data. Other insights can also be obtained from visualization. Tools to visualize data include:
Matplotlib and Seaborn (Python): Libraries for creating static, animated, and interactive plots.
Tableau: A powerful tool for creating dashboards and visual analytics.
ggplot2 (R): A popular data visualization package.
Machine Learning
Machine learning is a game changer for a data scientist. Although outliers and trends can be found by visualizing data, most of the complex insights are not possible to extract from visualization. Machine learning serves these purposes. By using a machine learning model, one can find complex insights and also predict future values. Without it, data scientists would miss out on a powerful tool and lag innovation. The key machine learning models are:
Supervised Learning: Supervised learning is those that learn from labeled data. Some important supervised algorithms are linear regression, decision trees, random forests, and gradient boosting.
Unsupervised Learning: Unsupervised learning models are those that learn from unlabeled data. Some important models are clustering (K-means, hierarchical) and dimensionality reduction (PCA).
Deep Learning: Deep learning is a special case of machine learning. It works like the human brain and extracts complex information from a vast amount of data. It excels at complex tasks like image and speech recognition, text processing, etc. This technique offers a sophisticated method to extract complex insights from large-scale data.
Soft Skills and Domain Knowledge
Communication Skills
Communication skills are as important as technical stuff for a data scientist. The real value of a data scientist comes from their ability to convey complex findings clearly and understandably to non-technical stakeholders; otherwise, all efforts will go in vain. Therefore, a data scientist needs to translate data into actionable knowledge. So, data scientists should be good at:
Storytelling with Data: Crafting compelling narratives around your findings.
Presentation Skills: Using tools like PowerPoint or Google Slides to present your results clearly.
Domain Expertise
While it's not mandatory for data scientists to be domain experts, having domain knowledge can significantly enhance their effectiveness. Domain knowledge will help distinguish meaningful patterns and noise and identify the most relevant features.y
Conclusion
Embarking on the journey to become a data scientist is both challenging and rewarding. By following this roadmap and continuously honing your skills, you can navigate the complexities of data science and carve out a successful career in this exciting field. Remember, the key is persistence and a passion for learning. Happy data science journey!
© 2024. All rights reserved.